1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
|
global A; %#ok
% 此处仅作演示,实际编程过程中应避免使用全局变量。
A = [...
1, -2; ...
-2, 10 ...
];
x_0 = [150, 100].';
eta = 1.2e-2;
gamma = 0.8;
max_iter = 1000;
dim1_space = linspace(-200, 200, 1e2);
dim2_space = linspace(-200, 200, 1e2);
[X, Y] = meshgrid(dim1_space, dim2_space);
Z = arrayfun(@(x, y) dst_function([x; y]), X, Y);
% 三维曲面图
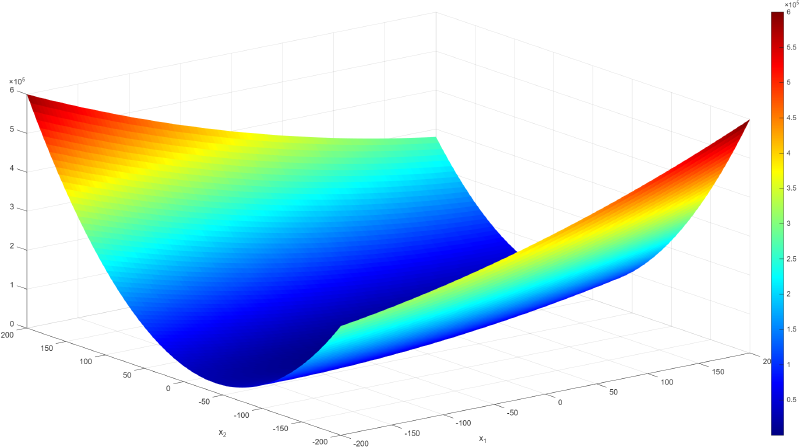
figure;
surf(X, Y, Z, 'EdgeColor', 'none');
colormap(jet);
colorbar;
xlabel('x_1');
ylabel('x_2');
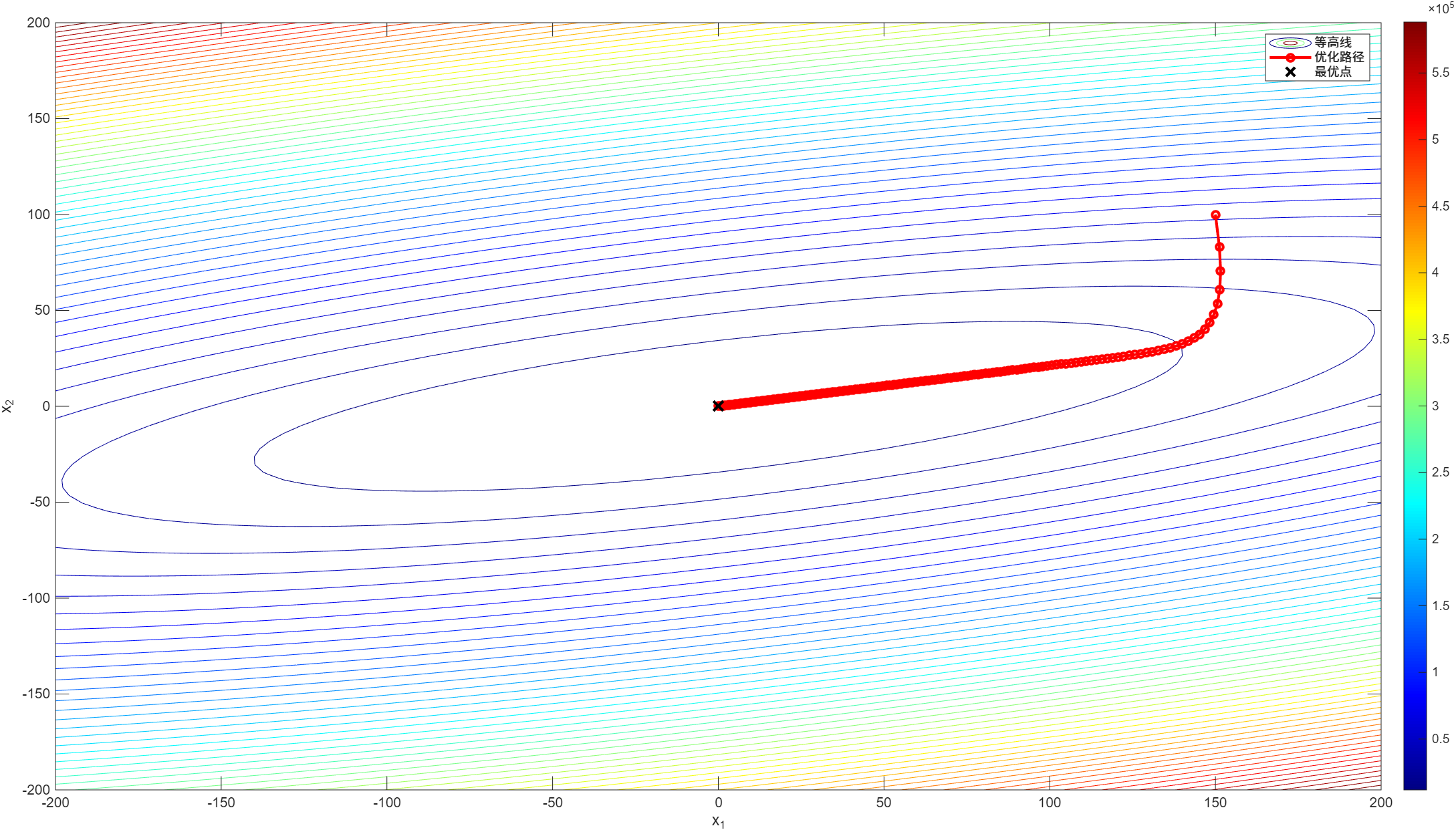
[x_opt, x_history] = gradient_descent(x_0, eta, max_iter);
% 绘制优化路径
figure;
contour(X, Y, Z, 50);
colormap(jet);
colorbar;
hold on;
plot(x_history(1, :), x_history(2, :), 'ro-', 'LineWidth', 2, 'MarkerSize', 5);
xlabel('x_1');
ylabel('x_2');
% 绘制最优点
hold on;
plot(x_opt(1), x_opt(2), 'kx', 'LineWidth', 2, 'MarkerSize', 10);
legend('等高线', '优化路径', '最优点');
fprintf('Gradient 最优点: (%.4f, %.4f), 迭代次数: %d\n', x_opt(1), x_opt(2), size(x_history, 2) - 1);
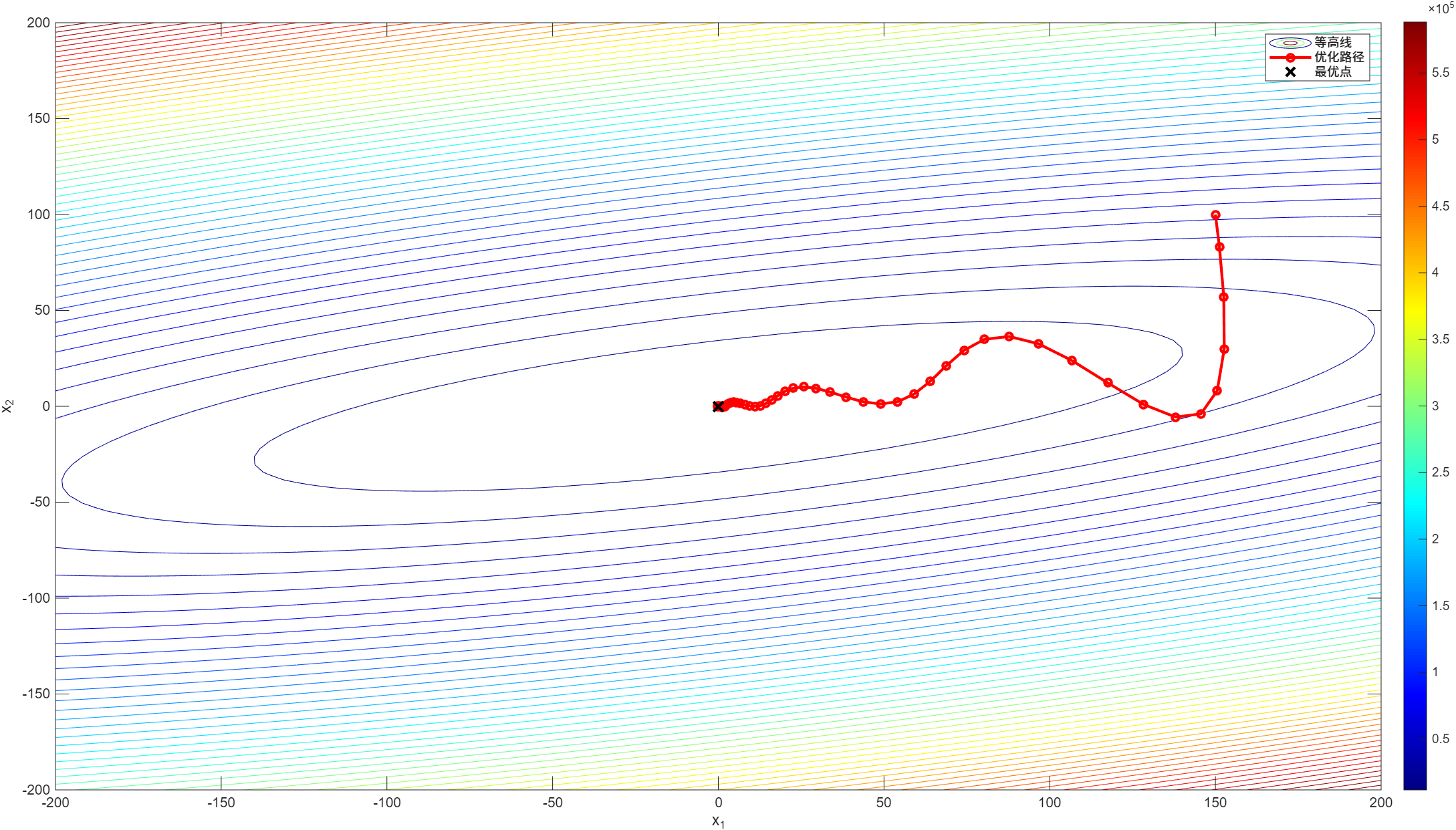
[x_opt, x_history] = momentum_method(x_0, eta, gamma, max_iter);
% 绘制优化路径
figure;
contour(X, Y, Z, 50);
colormap(jet);
colorbar;
hold on;
plot(x_history(1, :), x_history(2, :), 'ro-', 'LineWidth', 2, 'MarkerSize', 5);
xlabel('x_1');
ylabel('x_2');
% 绘制最优点
hold on;
plot(x_opt(1), x_opt(2), 'kx', 'LineWidth', 2, 'MarkerSize', 10);
legend('等高线', '优化路径', '最优点');
fprintf('Momentum 最优点: (%.4f, %.4f), 迭代次数: %d\n', x_opt(1), x_opt(2), size(x_history, 2) - 1);
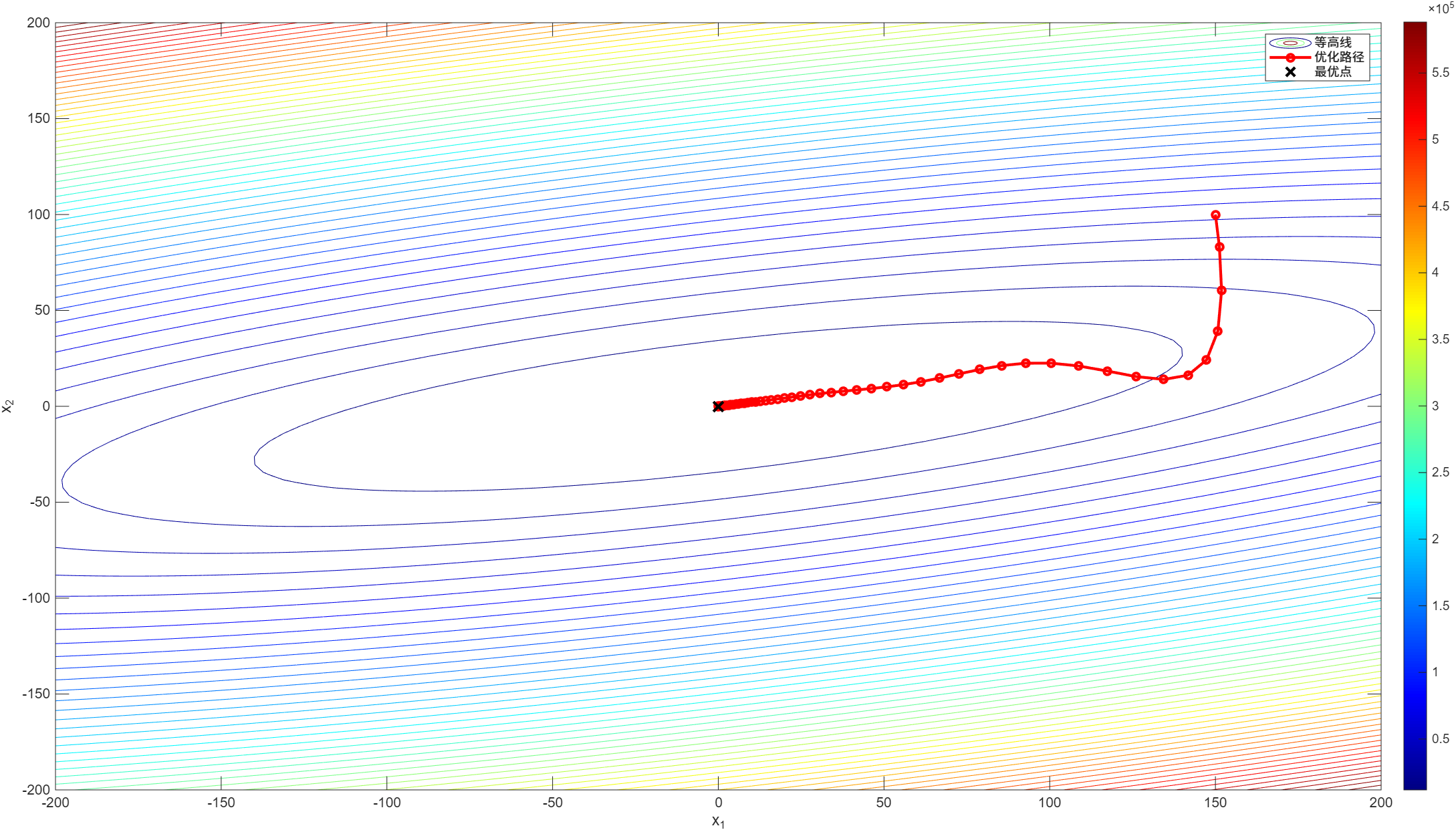
[x_opt, x_history] = nesterov_method(x_0, eta, gamma, max_iter);
% 绘制优化路径
figure;
contour(X, Y, Z, 50);
colormap(jet);
colorbar;
hold on;
plot(x_history(1, :), x_history(2, :), 'ro-', 'LineWidth', 2, 'MarkerSize', 5);
xlabel('x_1');
ylabel('x_2');
% 绘制最优点
hold on;
plot(x_opt(1), x_opt(2), 'kx', 'LineWidth', 2, 'MarkerSize', 10);
legend('等高线', '优化路径', '最优点');
fprintf('Nesterov 最优点: (%.4f, %.4f), 迭代次数: %d\n', x_opt(1), x_opt(2), size(x_history, 2) - 1);
function [x_opt, x_history] = gradient_descent(x_0, eta, max_iter)
x_history = zeros(length(x_0), max_iter+1);
x_history(:, 1) = x_0;
x = x_0;
for i = 1:max_iter
grad = dst_function_gradient(x);
x = x - eta * grad;
x_history(:, i+1) = x;
if norm(grad) < 1e-6 % 梯度足够小,认为收敛
x_history = x_history(:, 1:i+1); % 截断历史记录
break;
end
end
x_opt = x;
end
function [x_opt, x_history] = momentum_method(x_0, eta, gamma, max_iter)
x_history = zeros(length(x_0), max_iter+1);
x_history(:, 1) = x_0;
x = x_0;
m = zeros(size(x_0));
for i = 1:max_iter
grad = dst_function_gradient(x);
m = gamma * m + eta * grad;
x = x - m;
x_history(:, i+1) = x;
if norm(grad) < 1e-6 % 梯度足够小,认为收敛
x_history = x_history(:, 1:i+1); % 截断历史记录
break;
end
end
x_opt = x;
end
function [x_opt, x_history] = nesterov_method(x_0, eta, gamma, max_iter)
x_history = zeros(length(x_0), max_iter+1);
x_history(:, 1) = x_0;
x = x_0;
m = zeros(size(x_0));
for i = 1:max_iter
y = x - gamma * m; % 计算预测点
grad = dst_function_gradient(y); % 在预测点计算梯度
m = gamma * m + eta * grad; % 更新动量
x = x - m; % 更新参数
x_history(:, i+1) = x;
if norm(grad) < 1e-6 % 梯度足够小,认为收敛
x_history = x_history(:, 1:i+1); % 截断历史记录
break;
end
end
x_opt = x;
end
%% 目标函数
function y = dst_function(x)
global A; %#ok
y = x.' * A * x;
end
function grad = dst_function_gradient(x)
global A; %#ok
grad = 2 * A * x;
end
|